[问题] 爬虫只抓得到标签名,但内容抓不到
楼主: bckkt (bckkt) 2018-04-26 19:28:23
大家好
这是我想爬的网站https://web2.sa8888.net/
在<div id="scheduleMiddle">下面的表格就是我想抓的资料
以下是我的程式码
driver = webdriver.Chrome(chrome_options=chrome_options)
driver.get("https://web2.sa8888.net/")
pageSource = driver.page_source
driver.close()
soup = BeautifulSoup(pageSource, "html.parser")
print(soup)
<div id="scheduleMiddle">下面显示不出来任何表格
就算print(soup.find_all('div',id="scheduleMiddle"))
也只会出现[<div id="scheduleMiddle"></div>]
请教大家有没有什么想法?
这是我想爬的网站https://web2.sa8888.net/
在<div id="scheduleMiddle">下面的表格就是我想抓的资料
以下是我的程式码
driver = webdriver.Chrome(chrome_options=chrome_options)
driver.get("https://web2.sa8888.net/")
pageSource = driver.page_source
driver.close()
soup = BeautifulSoup(pageSource, "html.parser")
print(soup)
<div id="scheduleMiddle">下面显示不出来任何表格
就算print(soup.find_all('div',id="scheduleMiddle"))
也只会出现[<div id="scheduleMiddle"></div>]
请教大家有没有什么想法?
作者: eri820503 (snoopyahoo) 2018-04-26 20:06:00
在这网站按ctrl+U你会发现找不到比分因为这网页是用POST的方式所以应该是要去抓有table资料的那个网页用request.post抓看看
楼主: bckkt (bckkt) 2018-04-26 20:23:00
用requests.post(Url2,headers=headers2).text 好像没差出来一样的结果
作者: ThxThx (洗洗睡) 2018-04-26 21:32:00
可以trace一下source code它只有minify过我大概看一下 它是用websocket去抓资料
作者: vi000246 (Vi) 2018-04-26 21:37:00
看起来是先把资料抓出来 再用js动态产生的你可以研究一下资料是何时载进来的你在左边的页签随便按一下 会发现scheduleMiddle有变化但是没有任何request 可能资料是一开始就载好了
作者: shadowjohn (转角遇到爱) 2018-04-27 10:04:00
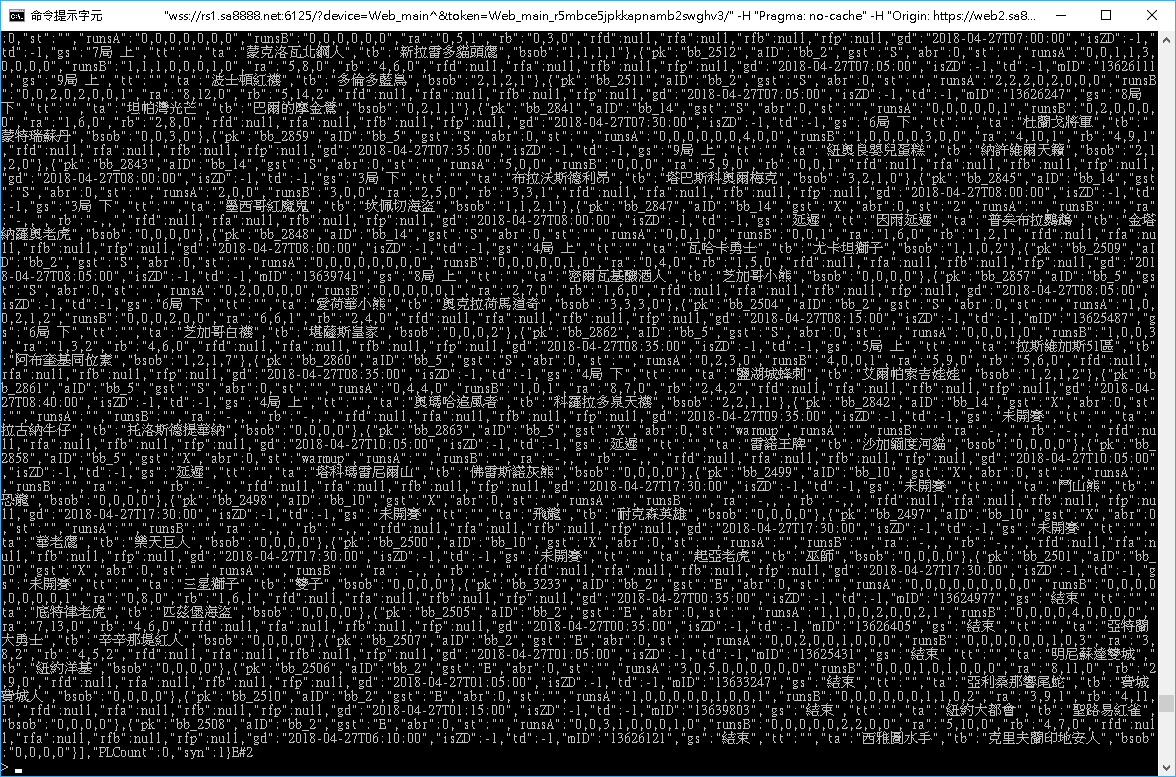 " target="_blank" rel="nofollow">
" target="_blank" rel="nofollow"> " target="_blank" rel="nofollow">资料在wss里面
" target="_blank" rel="nofollow">资料在wss里面楼主: bckkt (bckkt) 2018-04-27 12:03:00
TO楼上 我有看到WS有弹出很像资料的部分 我研究研究一下
继续阅读
[问题] Pycharm环境问题kiwistarRe: [问题] 用cmd开启chrome浏览器uranusjr[问题] 请问spyder有没有diff的功能?yimean[问题] pyinstaller安装GlassesKJ[问题] 用cmd开启chrome浏览器znmkhxrw[问题] 新手问问题 用librosa汇入音讯档错误ddmanddman[售书] 已售出 Python for everybodyethan5566[问题] 关于open()kiwistar[问题] 筛选字段符合特定值条件的各字段筛出来ademon[问题] 最近要爬xml档案,请问有xml资料网站吗?VAIOBIOS